Document Distance: Program Version 3
Problem Definition | Data Sets | Programs: v1 - v2 - v3 - v4 - v5 - v6 | Programs Using Dictionaries
Ah - the problem is that concatenating two lists takes time proportional to the sum of the lengths of the two lists, since each list is copied into the output list!
Therefore, building up a list via the following program:
L = []
for i in range(n):
L = L + [i]
takes time Θ(n2) (i.e. quadratic time), since the copying
work at the ith step is proportional toi, and
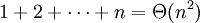
On the other hand, building up the list in the following way takes only Θ(n) time (i.e. linear time), since appending doesn't require re-copying the first part of the list, only placing the new element at the end.
L = []
for i in range[n]:
L = L.append(i)
So, let's change our get_words_from_line_list from:
def get_words_from_line_list(L):
"""
Parse the given list L of text lines into words.
Return list of all words found.
"""
word_list = []
for line in L:
words_in_line = get_words_from_string(line)
word_list = word_list + words_in_line
return word_list
to:
def get_words_from_line_list(L):
"""
Parse the given list L of text lines into words.
Return list of all words found.
"""
word_list = []
for line in L:
words_in_line = get_words_from_string(line)
# Using "extend" is much more efficient than concatenation here:
word_list.extend(words_in_line)
return word_list
(Note that extend appends each element in its argument list to the end of the word_list; it thus takes time proportional to the number of elements so appended.)
We call our revised program docdist3.py (PY).
If we run the program again, we obtain:
>docdist3.py t2.bobsey.txt t3.lewis.txt
File t2.bobsey.txt : 6667 lines, 49785 words, 3354 distinct words
File t3.lewis.txt : 15996 lines, 182355 words, 8530 distinct words
The distance between the documents is: 0.574160 (radians)
3838997 function calls in 84.861 CPU seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 :0(acos)
1241849 4.710 0.000 4.710 0.000 :0(append)
22663 0.101 0.000 0.101 0.000 :0(extend)
1277585 4.760 0.000 4.760 0.000 :0(isalnum)
232140 0.814 0.000 0.814 0.000 :0(join)
345651 1.254 0.000 1.254 0.000 :0(len)
232140 0.784 0.000 0.784 0.000 :0(lower)
2 0.001 0.000 0.001 0.000 :0(open)
2 0.000 0.000 0.000 0.000 :0(range)
2 0.014 0.007 0.014 0.007 :0(readlines)
1 0.010 0.010 0.010 0.010 :0(setprofile)
1 0.000 0.000 0.000 0.000 :0(sqrt)
1 0.006 0.006 84.851 84.851 <string>:1(<module>)
2 44.533 22.267 44.577 22.289 docdist3.py:108(count_frequency)
2 11.296 5.648 11.296 5.648 docdist3.py:125(insertion_sort)
2 0.000 0.000 84.507 42.254 docdist3.py:147(word_frequencies_for_file)
3 0.184 0.061 0.327 0.109 docdist3.py:165(inner_product)
1 0.000 0.000 0.327 0.327 docdist3.py:191(vector_angle)
1 0.012 0.012 84.846 84.846 docdist3.py:201(main)
2 0.000 0.000 0.015 0.007 docdist3.py:51(read_file)
2 0.196 0.098 28.618 14.309 docdist3.py:67(get_words_from_line_list)
22663 13.150 0.001 28.321 0.001 docdist3.py:80(get_words_from_string)
1 0.000 0.000 84.861 84.861 profile:0(main())
0 0.000 0.000 profile:0(profiler)
232140 1.492 0.000 2.276 0.000 string.py:218(lower)
232140 1.543 0.000 2.357 0.000 string.py:306(join)
Much better! We shaved about two minutes (out of about three) on the running time here, by changing this one routine from having quadratic running time to having linear running time.
There is a major lesson here: Python is a powerful programming language, with powerful primitives like concatenation of lists. You need to understand the cost (running times) of these primitives if you are going to write efficient Python programs. See Python Cost Model for more discussion and details.
Are there more quadratic running times hidden in our routines?
The next offender (in terms of overall running time) is count_frequency, which computes the frequency of each word, given the word list. Here is its code:
def count_frequency(word_list):
"""
Return a list giving pairs of form: (word,frequency)
"""
L = []
for new_word in word_list:
for entry in L:
if new_word == entry[0]:
entry[1] = entry[1] + 1
break
else:
L.append([new_word,1])
return L
This routine takes more than 1/2 of the running time now.
Can you improve it? Is this quadratic?