
These notes were prepared by Petros Komodromos.
Contents
- Functions: declarations, definitions, and, invocations
- Inline Functions
- Function Overloading
- Recursion
- Scope and Extent of Variables
- References
- Pointers
- Function call by value, References and Pointers
- Pointers to functions
- 1-D Arrays
- Strings as arrays of char
- Arrays of pointers
- 2-D and higher dimensions arrays
- Return by reference functions
- Dynamic memory allocation
- The sizeof operator
- Data structures
- Introduction to classes and objects
1\. Functions
A function is a block of code which performs specific tasks and can be called from another point of our program. After the execution of all statements of a function, control returns to the point from where the function was initially invoked, and the next executable statement is executed. With functions we can organize components of a program into sub-units using procedural abstraction. This allow us to break a complex problem into several small subproblems that can be handled easier by separate blocks of code.
main() is a special function that is invoked whenever the program is executed. Upon its return the execution of the program is terminated. It typically returns an int, which by convention is equal to zero when there are no problems. In contrast, a nonzero value indicates an error.
The following three steps are required to use a function:
(i) Function declaration or prototype (optional): It informs the compiler that the specified function exists and that its definition appears somewhere else in one of the source code files. In particular, it specifies its name, and parameters. By providing information about certain characteristics of the function, before invocation statements, the compiler is able to make checks for possible inconsistencies in function calls.
The function declaration specifies the function name, which should follow basic naming restrictions, the number and data types of the arguments to be passed to the function and the data type of the returned value. The keyword void is used when the function does not return a value or/and has no arguments. It is also allowable to use empty parameter list, i.e. empty parentheses, but according to the Standard C++, the return type must be explicitly specified.
The name and the data type of the parameters of a function constitute the function signature which uniquely identifies the function.
The declaration is optional if the definition appears before any function call. However, it is a good practice to always provide function declarations. They should preferably be provided in a header file, which can be included whenever it is necessary. A function can be declared multiple times in a program, and, therefore, a header file with declarations can be included several times as well.
returnType functionName(param1Type param1Name, param2Type,…..);
The return type of a function can be any data type, either built-in or user-defined. It is useful, although optional, to provide the names of the arguments for documentation purposes. A function can return a single value, which can also be a data structure, or an object, when it returns back at the invocation point. If no value is returned then the return type of the function should be defined as void.
e.g: int fun1(double, int);
void fun2( double x, double y);
float fun3(void);
(ii) Function definition: The function definition consists of the function definition header and the body of the function definition. Although the definition header looks like the declaration, the names of the local parameters are required. Inside the function body the provided statements are executed. More specifically, a function definition consists of 4 parts:
a return type
a function name
an argument list
the function body
A function declaration is similar to the header of the function definition, providing the return type, name, and parameter list of the function. The function definition must appear once, except in the case of an inline function, providing the body of the function enclosed in curly braces.
When passed-by-value is used, the parameter names are associated with the values passed during function invocation, and they are actually local variables whose memory is released upon exiting the function. When a return statement is encountered control returns to the point from where the function was invoked.
returnType functionName(par1Type par1Name, par2Type par2Name, …..)
{
function body
}
e.g: void fun2(float x, double yy)
{
cout << “\n x+y = " << x+yy;
}
(iii) Function calling (or, function invocation): A function is invoked by writing its name followed by the appropriate arguments separated by commas and enclosed in parentheses:
function_name(arg1, arg2);
If the data types of the arguments are not the same with the corresponding data types of the parameters of the function then, either an implicit conversion is done, if possible, or a compile-time error occurs. In case of an implicit conversion in which accuracy may be lost, e.g. converting a double to an int, a warning should be issued during compilation.
Functions work with copies of the arguments when they are called-by-value (i.e. without using references). Upon entering the function memory is temporarily allocated in order to store the passed values. After the function has been executed, the control returns to the calling function and the values of the local variables and parameters that are called-by-value are lost, since the corresponding memory is no longer reserved. The only exception is when we deal with a static local variable.
/* Example on functions */
#include <iostream.h>
#include <stdio.h>
double get_max(double x , double y);
void print_max(double x , double y);
main()
{
double x=11, y=22 ;
cout << “\n Max = " << get_max(x,y) << endl;
print_max(x,y);
}
double get_max(double x , double y)
{
if(x>y)
return x;
else
return y;
}
void print_max(double x , double y)
{
if(x>y)
cout << " Max = " << x << endl;
else
cout << " Max = " << y << endl;
}
Output
Max = 22
Max = 22
Default Arguments of a Function
Some, or all, arguments of a function can be specified and used in case only some, or no, arguments, respectively, have been provided at the function call. Whenever less than the total number of expected arguments are provided, the specified defaults values are used for the corresponding right-most arguments, i.e. the provided values by the function call are used for the left-most parameters and the remaining parameters on the right take their specified default values. Therefore, all parameters without default values must appear first in the parameter list.
/* Exaple on default arguments to a function */
void fun(double a=11.1, int b=22, double c=7.6);
int main(void)
{
fun();
fun(34.9);
fun(5.6, 3);
fun(12.4, 3, 19.5);
return EXIT_SUCCESS;
}
void fun(double a, int b, double c)
{
cout << " a = " << a << " b = " << b <<” c = " << c << endl;
}
Output a = 11.1 b = 22 c = 7.6
a = 34.9 b = 22 c = 7.6
a = 5.6 b = 3 c = 7.6
a = 12.4 b = 3 c = 19.5
2. Inline Functions
Using functions saves memory space because all the calls to a particular function execute the same code, which is provided only once. However, there is an overhead due to the extra time required to jump to the point that the instructions of that function are provided and then return back to the invocation point. In some cases, where very small functions are used repeatedly, it may be more efficient to have the code incorporated at the point of the function call instead of actually calling the function, so as to avoid the associated overhead. Inline functions can be used for this purpose. An inline function is a regular function with a suggestion to the compiler to insert the instructions at the points where the function is called.
A definition of a function as inline suggests to the compiler to expand the body of the function at all points where it is invoked. An inline function is expanded by the compiler during the compilation phase and not by the preprocessor (during macro substitutions). This is useful for very short functions which may result in a computational overhead whenever they are called. Inline functions eliminate the overhead of function calls while allowing the usage of procedural abstraction.
A function is defined as inline using the keyword “inline” before its header. The inline directive should be specified in the function definition, rather than in its declaration.
e.g.:
inline max(double x, double y)
{
…….. // statements
}
The compiler may, or may not, expand the function at its invocation points to avoid this overhead. However, it is necessary that the compiler sees the function definition, and not just the declaration, before it encounters the first function call, so as to be able to expand it there.
A disadvantage of inline functions is that if an inline function is modified, then all the source code files that use that function should be recompiled. This is necessary because, if the compiler follows the inline suggestion, the body of an inline function is expanded at any point where the function is called. In contrast, a non-inline function is invoked during run-time. Also, the inline function must be defined in every file that it is used, with identical definitions. an alternative way to avoid having multiple copies of the same function definition is to have the function definition in one file which can be included in all source code files that make use of the inline function.
3. Function Overloading
C++ allows function overloading, i.e. having several functions with the same name, in the same scope, as long as they have different signatures. The compiler can distinguish which one to actually invoke based on the data types of the parameter list of each one, which should be different, and the provided arguments. The only overhead from using overloaded functions is during compilation, i.e. there is no effect during run time.
The signature of a function is considered to be its name and parameters, specifically their number and data types. The return type of a function is not considered part of a function signature. When an overloaded function is called, the compiler selects the matching function among those with the same name using the data types of the provided arguments. The process in which a function is selected among a set of overloaded functions is called function overload resolution. The latter process follows certain rules based on the arguments provided at a function call. Briefly, the function overload resolution process first identifies all candidate functions, i.e. all visible functions with the same name. Candidate functions are selected based on the argument data types at the function call and considering possible conversions. Finally, the best matching function, if any, is selected among the remaining candidates based on how good the required conversions are.
/* Example on function overloading */
int min(const int x, const int y) ;
double min(const double x, const double y) ;
main()
{
int x,y,m;
x=3;
y=7;
cout << “\n min(x,y) = " << min(x,y) << endl;
double z=4.5, w=2.34 ;
cout << " min(z,w) = " << min(z,w) << endl;
}
int min(const int x1, const int x2)
{
if(x1<x2)
return x1;
else
return x2;
}
double min(const double x1, const double x2)
{
if(x1<x2)
return x1;
else
return x2;
}
Output
min(x,y) = 3 // int min(const int x1, const int x2) has been called
min(z,w) = 2.34 // double min(const double x1, const double x2) has been called
4. Recursion
An algorithm can have an iterative formulation, a recursive function, or both formulations combined. A function is said to be recursive if it calls itself. Each time that a function calls itself a new set of local variables is created. This set is independent of any other local variables created in previous calls, assuming that all calls are by value and no static local variables are used.
Typically a recursive function involves a recursive call to itself with a smaller problem to solve. This is the ‘divide-and-conquer’ approach which decomposes a problem into smaller ones with similar characteristics with the original problem. A recursive function should have, at its beginning, a base case that is tested to determine whether the recursive calls should be terminated.
The following two functions can be used to compute the factorial of a number. First, an iterative version is provided, followed by a recursive one.
_int factorialIterative(int n) _ // iterative version
{
int result=1;
while(n>1)
result *= n–;
return result;
}
int factorialRecursive(int n) // recursive version
{
if(n==0)
return 1;
return n*factorial_Recursive(n-1);
}
5. Scope and Extent of Variables
The scope of a variable is where in the program the variable is accessible and therefore it can be used, i.e. the scope defines where the variable can be used, or assigned. In general, variables are accessible only in the block in which they are declared. In C++ there are 3 different scopes: the local scope, the namespace scope, and the class scope.
A variable defined inside a function is a local (or automatic) variable. The scope of a variable that is defined in a compound block inside a function is limited inside that block. Local scopes can be nested. However, the parameters of a function have local scope and cannot be redeclared inside the function’s local scope, or inside any other nested local scopes in the function.
An entity that is defined outside any function or class definition has a namespace scope. User-defined namespaces can be defined using namespace definition, as we will see in a later recitation. For now we will consider only the global scope, which is a specific case of the namespace scope. In particular, the global scope is the outermost scope of a program. A global variable (or function) is a variable defined outside of all functions.
The scope of a global variable is universal, since it is accessible by all statements after its declaration or definition. In contrast, the scope of a local variable is local since it is accessible only inside the function in which it has been declared.
A global entity (i.e. variable, object, function) can be declared several times in the source-code files of program, while only one definition can appear. The only exception is inline functions that can have several definitions, identical however, one at each source code file. A global variable can be declared many times using the keyword extern to indicate that somewhere else (in another source code file) that variable is defined. Only one variable definition must be provided and it is only then that memory is allocated for the variable. If a global variable is not initialized at its definition it is automatically initialized to zero.
In addition, in C++, the user defined data types (classes) allow us to specify certain permissions for the access of data members of the objects we define using the classes we develop.
The extent or lifetime of a variable is the duration for which memory is reserved for it. The memory allocated for parameters and local variables is in general reclaimed upon returning from the function, and therefore, they have dynamic extent. In contrast, the global variables have static extent since the memory allocated for them is never reallocated. Local variables can also have static extent if the keyword static is used when they are defined.
There are 4 storage classes:
Automatic: Local variables, or objects, are local variables with dynamic extent, unless they have been defined as static. Memory is allocated for automatic variables and objects from the run-time stack upon entering the function and is automatically deallocated, i.e. released, upon exiting the function. If an automatic variable is not initialized then its value is unspecified since the allocated memory contains random information.
External: Global variables which, unless they have been defined as static, are accessible from any part of the code, i.e. in any file as long as either the global variable definition (and this can occur only once), or a declaration using the keyword extern (this can occur several times) is provided.
Static: Both local and global variables can be defined static using the static keyword. However, static local and static global variables are different.
Static local variables are initialized once, have extent, i.e. lifetime, throughout the program, but their scope, i.e. visibility, is limited to the function in which they are defined. Defining a local variable as static results in having static extent for that variable, i.e. the allocated memory for that variable is reserved until the termination of the program. Memory for a static local variable is allocated only once at the first time the function is entered and the memory with the currently stored value is retained and can be used during the next entry. An uninitialized static local variable is by default initialized to zero.
_
Static global variables_, or functions, are global variables, or functions, that are not accessible outside the file they are defined, i.e. their use is restricted only within the file they are defined.
Register: This storage class is similar with automatic with the only difference that it is suggested to the compiler to keep these particular variables in some registers in CPU so as to save time when these variables are frequently used, e.g. frequently used variable in a loop. An automatic variable can be declared to have register storage using the register keyword, e.g.: register int i;
Access of variables: A name resolution process determines, during compile time, to which particular entity, i.e. location in memory, a particular name (of a variable, function, object, etc.) refers, considering the provided name and the scope in which it is used.
Global Variables: variableName or :: variableName
Local Variables: variableName
Object Member Variables: object.variableName or point_obj -> variableName
or this -> variableName
If inside a function a local variable has the same name with a global variable, then the local variable hides the global. In C++ we can access the global variable using the scope resolution operator ::var, access the global var variable.
/* Example on scope and extent of variables */
#include <iostream.h>
extern double y; // external variable (defined in another file)
static double x=25.5; // static global variable
void fun(double x);
int main()
{
int x=3; // local variable
fun(x);
fun(::x);
fun(x);
}
static void fun(double x)
{
static int s=0; // static local variable
int n=0; // automatic (dynamic local) variable
cout << " n = " << n << “\t s =” << s
<< “\t x = " << x << endl;
}
Output
n = 0 s =0 x = 3
n = 0 s =0 x = 25.5
n = 0 s =0 x = 3
6. References
A reference serves as an alias (i.e. a nickname) for the variable or object with which it has been initialized. A reference is defined using an address-of operator (&) after the data type. References are typically used when a function is called, as an alternative to pointers, in order to be able to work on the actual variables that are used as arguments when calling the function, rather than with their values.
When a parameter of a function is defined to be a reference then that variable is said to be passed-by-reference, rather than by value. Since all operations on a reference are actually applied to the variable that it refers, the only way to assign a variable to a reference is during its definition, i.e. a reference is assigned a variable to which it refers during its definition. It is also possible to have a reference to a pointer as shown in the following section example.
e.g: double x=15.75, &rx= x; // rx is a reference to a double
_rx += 20; _ // x becomes equal to 35.75
7. Pointers
A Pointer variable is used to hold an memory location address. Every pointer has an associated data type that specifies the data type of the variable, or, in general, object, to which the pointer can point. Since pointers are variables that are used to store addresses of other variables, they must be defined before being used. A pointer is declared as a pointer to a particular type using the dereference operator (*) between the data type and the name of the pointer. Using the address stored by the pointer, the variable stored in that address can be indirectly manipulated.
e.g.: double *px, *py, x, z *pz ; int j, *pj, k ;
The memory storage allocated for a pointer is the size necessary to hold a memory address (usually an int). The address of a variable (i.e. the location in memory where it is stored) can be obtained using the address-of operator (&), e.g. &x gives the address (i.e. the memory location) where the variable (here x) is stored. A pointer can be assigned the value 0 or NULL to indicate that it points nowhere. However, it is not allowed to assign to a pointer an address that is used to store a different data type variable.
The address of a variable is stored in a pointer using the address-of operator, by an assignment such as: px =&x;. The value which is stored in an address pointed to by a pointer can be accessed using the dereference operator (*). The value of a pointer is the address that it points to. Dereferencing a pointer gives the value which is stored at the memory location stored as the value of the pointer.
e.g. double *px, x;
px = &x ;
*px = 25.5 ; // this is equivalent to assigning x=25.5
Pointers can be used in arithmetic, assignment, and comparison expressions. An integral value can be added to, or subtracted from, a pointer. According to the rules of pointer arithmetic, when adding (or subtracting) a value from a pointer, the new address memory that is assigned to the pointer is equal to the current memory address plus (or minus) the amount of memory required to store that particular data type whose address is stored by the pointer times the value that is added (or subtracted). A pointer can be incremented, decremented, or subtracted from another pointer. However, two pointers cannot be added, and, pointer multiplication and division are not allowed.
A special pointer that can be used to store any type of pointer is called a pointer-to-void, and can be defined using the keyword void as the data type. However, no actual manipulation of the contents of the address pointed to by a pointer to void can be performed directly. Since a pointer-to-void does not provide any data type information concerning the data stored in the memory at which it points, an explicit cast is required to specify the data type of the data stored there.
double x=10.75, *px=&x;
void *vp = &x;
cout << “\n x = " << x ;
cout << “\n *px = " << *px ;
// cout << “\n *vp = " << *vp ; // <——- Wrong!
cout << “\n *vp = " << *(static_cast <double*>(vp)) ; // ok
The following example demonstrates the use of both references and pointers:
/* Example on references and pointers*/
#include <iostream.h>
#include <stdlib.h>
int main(void)
{
int i=5, &ri = i ; // integer and reference to an integer
double x=24.5, *px=&x, *&rpx=px; // double, pointer and a reference to pointer to a double
ri++;
*px += 100;
*rpx += 1000;
cout << “\n i = " << i << “\t ri = " << ri;
cout << “\n x = " << x << “\t *px = " << *px
<< “\t *rpx = " << *rpx << endl;
return EXIT_SUCCESS;
}
Output
i = 6 ri = 6
x = 1124.5 *px = 1124.5 *rpx = 1124.5
8. Function Call by Value, by Reference and Using Pointers
Pointers and references provide ways to overcome the problems associated with the call-by-value. Often we need to change the values of variables within a function call and this is impossible using directly the call-by-value which passes only copies of the values of the provided parameters. These copies are lost upon exiting the function and only one value can be returned by the function. In addition, large user-defined objects are often passed as arguments to a function. In those cases, using call-by-value requires memory allocation and copying of the passing arguments to the corresponding parameters which can be too costly both in computational time and memory space. Finally, in some cases, we may need to return more than one value from a function.
Therefore, in many cases calling a function by-value does not help much. There are two alternative approaches, either using a call-by-reference, or sending with call-by-value the address of the objects that we want to pass as arguments and operate on them indirectly using pointers.
We can change variables in the function by passing them by reference in which case the local variables are aliases to the actual variable. To pass an argument by reference we need to declare this by using an address-of-operator (&) after the data type of the passing by reference argument. The function is then called by reference. When an argument is sent by reference, it means that an alias to the argument is used in the function to access the actual variable in the calling function. Then, all changes that take place are actually done on the variable that is used as an argument when the function was invoked. A reference serves as an alias for the object with which the function was called and is initialized once upon entering the function, i.e. a parameter that serves as a reference cannot refer to different variables or objects. In cases where we want to pass a large object, that we do not want to change, by-reference, in order to save the overhead from making a local copy to the function parameter, we can define the reference to be a const so as to prevent any accidental modifications of it.
An alternative way is to use**pointers** and pass the address of the variables which allows us to access the variables indirectly and change the values stored at those locations. This is indicated by an * operator after the data type of the argument that is passed as an address, since it is actually a pointer. Using addresses of variables as arguments to functions we can access indirectly and change the values of some variables of the calling function. In addition, memory needs to be allocated only for the pointer and not for the entire object, saving the time and space overhead of copying the arguments to the function parameters. In C++ an array is always passed by a pointer to its first element, i.e. it is never passed by value
The following example demonstrates the use of call by-value, by-reference and using pointers.
/* Example for call-by-value, call-by-reference and using pointers */
#include <iostream.h>
void fun(double x, double &y, double *z);
int main()
{
double x=11.1, y=22.2, z=33.3;
fun(x,y,&z);
cout << “\n x = " << x << “\t y = “
<< y << “\t z = " << z << endl;
}
void fun(double x, double &y, double *z)
{
x *= 2;
y *= 2; // using call by reference
*z *= 2; // using pointer to access the actual variable
cout << “\n x = " << x << “\t y = " << y << “\t z = " << *z << endl;
}
Output
x = 22.2 y = 44.4 z = 66.6
x = 11.1 y = 44.4 z = 66.6
9. Pointers to Functions
The name of a function is actually the address of the function in memory. A pointer to a function can be used as an argument to a function to allow us to selectively invoke one out of several different functions, depending on the name of the function we use as argument. To use a pointer to a function we need to declare it in the declaration and definition of the function, i.e. specify that the function accepts as an argument a pointer to another function. A pointer to function is defined using the function’s type, which consists of its return type and parameter list. For example, the following declaration declares that the function fun() has 3 arguments: an int, a pointer to a function that itself returns a double and has a float and an int as arguments, and a float.
double fun(int i, double (*f) (double, int), float);
A function name, in general, gives a pointer to that function, although an address-of-operator can also be used to get (explicitly) the same. A pointer to a function can also be initialized, or assigned a value. When calling the function to which the pointer points to, the pointer’s name, either by itself or dereferenced, can be used.
An example of a pointer to a function is presented below. The function compute() has 3 arguments: a pointer to a function, and 2 integers. The name of any function that returns a double and has two doubles as arguments can be provided in the function call of compute(). The provided function is then used inside the compute() function whenever f() is used.
/* Example of Pointers to functions */
#include <iostream.h> // pointers to a functions
double adding(double x, double y);
double subtracting(double x, double y);
double compute(double (*f)(double,double), int i, int j);
int main()
{
int x=7, y=3;
cout << “\n compute(adding,x,y) = " << compute(adding,x,y) << endl;
cout << " compute(subtracting,x,y) = “
<< compute(subtracting,x,y) << endl;
}
double compute(double (*f)(double,double), int i, int j)
{
return f(0.5*i,j); // The following is equally valid: return (*f)(0.5*i,j);
}
double adding(double x, double y)
{
return x+y;
}
double subtracting(double x, double y)
{
return x-y;
}
Output
compute(adding,x,y) = 6.5
compute(subtracting,x,y) = 0.5
10. 1-D Arrays
An array is used to store a set of values, or objects, of the same (either built-in or user- defined) data type, in one entity. An individual element of the array, i.e. a member of this set, can be accessed using the array’s name and an index which should be a value, or an expression, of integral type. The individual objects of an array are accessed by their position in the array using indexing with the index beginning from 0. Therefore, the last element of an n-size array has index equal to n-1. An array is defined using a pair of square brackets as shown below:
<data_type> <array_name> [size];
The dimension of the array, at the array definition, must be a constant expression, i.e. to be known during compilation, except in the case in which all elements of the array are explicitly initialized at the definition. If less elements of an array are initialized, according to the provided size during definition, the remaining elements are initialized to zero, e.g.:
double x[5]; // an array of 5 doubles is defined
int y[]={ 3 , 56, 4, 6 }; // an array of 4 int
float z[6] = { 0. }; // all 6 float members are set to 0.
int h[7]={ 13 , 26, 42 }; // an array of 4 int
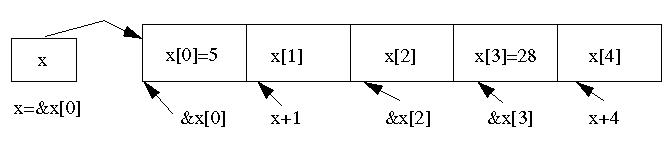
When an array is defined, the appropriate amount of consecutive memory is allocated. Memory is also allocated for a constant pointer that is associated with the name of the array and which stores the beginning address of the memory allocated for the array. Therefore, the array name is itself a constant pointer that stores the address of the first element of the array, i.e. the address of memory where the first element is stored, e.g. x is equal to &x[0]. The name of an array is a constant pointer because it cannot be assigned a different address. Since the name of an array is a pointer, an individual element of an array can be alternatively accessed using pointer arithmetic, instead of using the index notation. In essence, the index notation mat[i] is equivalent to *(mat+i).
You should be particularly careful not to exceed the range of an array since the compiler does not make such checks. However, in most cases memory is wasted when using arrays since we often allocate much more memory that we will probably ever need. Dynamic memory allocation can be used to avoid this waste of memory by allocating dynamically during execution the exact required memory, e.g.:
double x[5];
x[0]= 5;
x[3] = x[0]+23;
/* Example on references, pointers and arrays */
#include <iostream.h>
#include <stdio.h>
main()
{
double x=11.1 , *px;
double &rx = x;
cout << “\n x = " << x << endl;
cout << " rx = " << rx << endl;
rx = 33.3;
cout << “\n x = " << x << endl;
cout << " rx = " << rx << endl;
px = &x;
ios::sync_with_stdio();
printf( “\n px = %p \n” , px );
ios::sync_with_stdio();
cout << " *px = " << *px << endl;
*px = 44.4;
cout << “\n x = " << x << endl;
cout << " *px = " << *px << endl;
double mat[] = { 10 , 20 , 30};
px = mat ;
cout << “\n mat[0] = " << mat[0] << endl;
cout << “\n px = " << *px++ << endl;
cout << " px = " << *px << endl;
cout << “\n px[1] = *(px+1) = " << *(px+1) << endl;
cout << " mat[2] = *(mat+2) = " << *(mat+2) << endl;
}
Output
x = 11.1
rx = 11.1
x = 33.3
rx = 33.3
px = 7fffae20
*px = 33.3
x = 44.4
*px = 44.4
mat[0] = 10
px = 10
px = 20
px[1] = *(px+1) = 30
mat[2] = *(mat+2) = 30
11. Strings as Arrays of char
In C++ there are two string representations: the traditional way of an array of characters, and, the newer standard C++ string class. For now, we consider the former string representation.
The string is stored as an array of char with a special character at the end ’\0’, which is called the terminator character, since it is used to indicate the end of the string. Therefore, memory space for an extra character must be provided to be able to store the terminator character.
Several library functions that can be used to manipulate strings are provided by the Standard C-library. To use them, the cstring header file, which contains their declarations, must first be included. The most commonly used are the following:
strcpy(char str1[] , char str2[]): strcpy copies the contents of str2 (including the terminator character) into str1
strcmp(char str1[] , char str2[]): strcmp compares the two strings alphabetically, returning zero if they are exactly the same, otherwise a nonzero value
strlen(char str1[]): strlen counts the number of characters in the string (not including the terminator character)
Although an array of strings can be initialized using the string notation (i.e. a literal enclosed in double quotes), it is not possible to assign a string to an array of char after its definition. A C-standard library need to be used to make this copying, e.g.:
char s1[] = “MIT” , char s2[4] ;
strcpy (s2,“MIT”);
char str3[] = { ‘M‘ , ‘I‘ , ‘T‘ , ‘\0‘ };
The following example demonstrates how a string can be defined, initialized or assigned a literal string, how can be modified, etc.
/* Example for strings as arrays of char */
#include <iostream.h>
#include <cstring>
int main(void)
{
char str1[] = “test” ;
const char *str2 = “Test” ;
char str3[50] ;
cout << “str1 and str2 are " ;
strcmp(str1,str2) ? cout << “different” << endl : cout << “the same” << endl;
cout << “\n str1 = " << str1 << endl ;
cout << " str2 = " << str2 << endl ;
strcpy(str3,str1);
strcat(str3,str2);
cout << “\n str3 = " << str3 << endl ;
str3[0] = ‘T’;
cout << " str3 = " << str3 << “\t length = “
<< strlen(str3) << endl ;
return 1;
}
Output
str1 and str2 are different
str1 = test
str2 = Test
str3 = testTest
str3 = TestTest length = 8
12. Arrays of Pointers
Since pointers are variables we can have arrays of pointers. Such arrays are often used to store the location in memory of a collection of data with the same type. Each element of an array of pointers is a pointer which can be used to point to a memory location.
e.g.: _double *pd[100]; _ // pd is an array of 100 pointers to doubles
_char *pc[20]; _ // pc is an array of 100 pointers to char
13. 2-D and Higher Dimensions Arrays
Multidimensional arrays (of any dimension) can be defined using additional brackets, one for each dimension. A multidimensional array can be initialized similarly to a 1-D array, with the option to use nested curly braces to group the data along the different dimensions (e.g. rows).
double mat2[6][3];
double mat3[5][3][2];
double m[][] = { {3 , 6.2 , 0.5} , { 23.7 , 0.75 , 4.8 } };
double m[3][10] = { {4.5} , {13.7} };
Although it is natural to think a 2-D array having a rectangular 2-D form, the elements of arrays (of any dimension) in C++ are actually stored in a contiguous memory location. The following graph shows how a 2-D array is stored. The top graph shows the virtual representation of a 2-D array, while the bottom one shows how actually it is stored in memory:
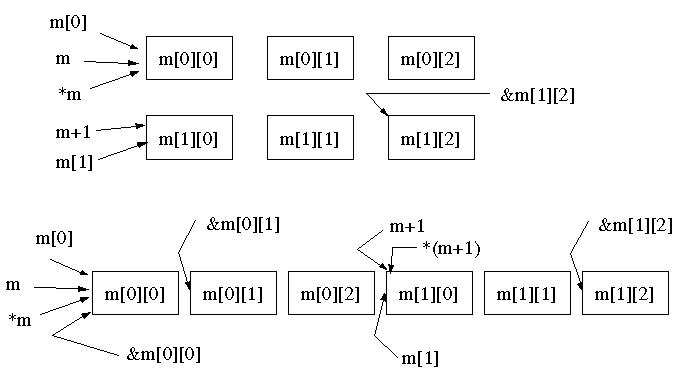
Therefore, the following expressions are exactly equivalent to m[i][j]:
*(m[i]+j)
(*(m+i))[j]
*((*(m+i))+j)
*(&m[0][0]+WIDTH_SIZE*i+j)
/* Example for 2-D arrays */
#include <iostream.h>
#include <stdlib.h>
#include <iomanip.h>
#define ROW_SIZE 4
#define COL_SIZE 7int main()
{
double m[ROW_SIZE][COL_SIZE] = { { 4.5 , 0.45 } ,
{ 13.7 , 67.3 , 17.7 } , { 2.6 } };
int i,j;for(i=0;i<ROW_SIZE;i++)
{
cout << endl;
for(j=0;j<COL_SIZE;j++)
cout << " " << setw(5) << m[i][j];
}
return EXIT_SUCCESS;
}
**Output
**
4.5 0.45 0 0 0 0 0
13.7 67.3 17.7 0 0 0 0
2.6 0 0 0 0 0 0
0 0 0 0 0 0 0
14. Return by Reference Functions
A function can either return nothing, in which case it is declared as void and a return statement is optional, or return a value. In the latter case the default is to return a value by-value, i.e. a copy of the value that is returned is passed to the function from where the terminating function was called. However, there are some cases that it is preferable to return a value by-reference, or using pointers. For example, it may be useful to return a reference to an object or variable so as to be able to manipulate it, or it may be more efficient to pass by reference, or using a pointer, a large user-defined object to avoid the overhead due to copying it.
When a function returns by-reference, i.e. returns a reference to a variable or object, the function call can be placed in the LHS of an assignment statement. However, a variable, or object, with local scope cannot be returned by-reference, since the memory allocated for it is released upon exiting the function.
The following example shows one such a case, in which a reference to a specific element of an array is returned.
/* Example on return by reference */
double & fun(int i, double *x);
void main(void);void main(void)
{
double x[10]={0};
fun(3,x) = 57.6;
cout << “\n x[5] = " << x[5] << endl;
cout << “x[6] = " << x[6] << endl;
}
double & fun(int i, double *x)
{
return x[2*i];
}
**Output
**
x[5] = 0
x[6] = 57.6
15. Dynamic Memory Allocation
Memory can be obtained dynamically from the system, in particular from a pool of free memory named the free store (or heap), after the program has been compiled, i.e. during execution, using the new operator. This operator can be used to allocate sufficient memory for one or more variables of any data type (standard or user-defined), i.e. for a single variable, or object, or an array of variables, or objects.
Memory is allocated dynamically using the operator new followed by a type specifier and in the case of an array followed by the array size inside brackets. In the case of a single variable an initial value can also be provided within parentheses. The new expression returns the address of the beginning of the allocated memory and can be stored in a pointer in order to access that memory indirectly. If the dynamic memory allocation is not successful a NULL (i.e. a 0 value) is returned by the operator new. The following statements allocate memory for one float and an int, and the address of that memory location is returned and then assigned to the pointer pf and pi, respectively. Dynamically allocated memory, if not explicitly initialized, is uninitialized with random contents.
float *pf = new float; // allocate memory for a float
int *pi = new int(37); // allocate memory for an int and assign an initial value to it
Similarly, the following statement allocates contiguous memory for a size number of doubles and then the address of the beginning of that memory is returned and assigned to the pointer pd. The size does not have to be a constant, i.e. known at compilation, but can be specified during execution of the program according to the program demands. However, there is no way to initialize the members of a dynamically allocated array.
double *pd = new double[size];
In contrast, to allocate memory for an array of doubles the size must be known prior to compilation, i.e. the size should be a constant. In the following definition of an array the name of the array is a constant pointer, since it cannot point anywhere else, while in the previous example pd can be used to store any memory address where a double is stored.
double mat[50];
Multidimensional arrays can also be dynamically allocated using a new expression. However, only the left-most dimension can be specified at run-time. The other dimensions need to be defined at compilation time, i.e. to have a constant size, e.g.:
_double (*pmat)[100] = new double [size][100]; _ // size does not need to be a constant
The allocation and release of memory for variables for which memory is statically allocated is done automatically by the compiler. Memory of local variables is automatically released upon exiting the function, unless they are defined as static, and that memory can be used for other purposes. However, dynamically allocated memory is not released upon exiting a function and care must be taken to avoid losing the address of that memory, resulting in a memory leak. Dynamic allocation and deallocation of memory is a programer’s responsibility. When memory that is allocated dynamically is not needed any more, it should be released using the delete operator as shown in the following example which is based on the previous one:
delete ps;
delete [] pd;
The brackets are required when the pointer points to consecutive memory of a dynamically allocated array, in order to release all memory that has been allocated earlier. Only memory that has been dynamically allocated (i.e. using the new operator) can be released using the delete operator.
Its a good practice to set the value of a dangling pointer, a pointer that refers to invalid memory, such as a pointer that was used to point to a released memory, to NULL (or 0). Then, we avoid the error of trying to read or write to an already released memory location. However, it is not wrong to apply the delete expression to a pointer that is set to 0, because a test is performed before actually applying the delete operator on the pointer. Therefore, there is no reason to check whether the pointer is set to 0. The delete operator should not be applied twice to the same memory location, e.g. by mistake when having two pointers store the same memory location, because it may lead to corruption of data that have already been stored after the first release of the memory.
If the available memory from the program’s free store is exhausted, than an exception is thrown, and as we’ll see later there are ways to rationally handle such exceptions.
16. The sizeof Operator
The sizeof operator gives the size in bytes of a variable, a built-in data type, or a user-defined data structure, or a class, it can be used to determine the number of bytes that are required to store a certain object.
e.g:
int i, mat[10]; double d; // On an athena SGI or SUN workstation:
sizeof(char); // returns 1 (byte)
_sizeof(int); sizeof i; _ // returns 4 (bytes)
_sizeof d ; _ // returns 4
sizeof mat; // returns 40
17. Data Structures
A data structure is very similar to a class and it is not often used in C++, since more features are provided by a class. A structure can be used to store as a single entity several different variables not necessarily of the same data type. Structures in C++ have some extra features from the structures in C, such as access restriction capabilities, member functions and operator overloading.
A data structure is defined using the keyword struct, followed by the name of the structure and then its body where it is defined. Then, to define an instance of the data structure we can use its name directly (the struct keyword is not required as in C). To access a member of a data structure the dot or the arrow operator are used depending on whether we have the actual data structure instance or a pointer to it.
Structures can be passed to a function as any other variable, i.e. by value, by reference, or, using pointers. Because data structures are large in size, pass by value is typically not preferred, in order to avoid the copy overhead.
/* Example on data structures */
struct point
{
double x;
double y;
};
typedef struct point Point; // the typedef is not necessary in C++int main()
{
Point p; // p is a data structure point
point *pp; // pp is pointer to a point data structurep.x = 3.2; // using the dot operator
pp = &p;
pp -> y = 7.5; // using the arrow operatorcout << “\n x = " << pp->x << “\t y = " << (&p) -> y << endl;
struct point p2 = {4.7 , 9.2}; // A data structure instance can be intialized using
pp = &p2; // comma separated values enclosed in curly braces
cout << " x = " << pp->x << " y = " << p2. y << endl;
}
**Output
**
x = 3.2 y = 7.5
x = 4.7 y = 9.2
Note: The typedef allow us to assign a name for a specific data type, built-in or user defined, and then, use it as a type specifier. In the above example, struct point p and Point p are exactly equivalent, since the following typedef has been defined: typedef struct point Point; The typedef keyword is followed by a data type and an identifier that we want to specify as alias to that data type.
18. Introduction to Classes and Objects
A class is a user defined specification that encapsulates in a single entity both data and functions that can operate on them. An object is an instance of a class and the class/object relation is similar to the built-in data type/variable relation.
A class is defined using the keyword class followed by the name of the class. A class typically has**data members, which contain the data that is stored using the class; member functions, which are functions that operate on these data; constructors, that are member functions with a name the same as the class name and are executed upon a creation of an instance of the class in order to make the proper initialization; destructors, that are used when an instance of a class goes out of scope; and many other features such as operatoroverloading**, declarations of friend functions, etc.
The following simple example demonstrates the use of a Point class with some of the most basic features of a class.
/* Example on classes and objects */
class Point
{
private:
double x,y;public:
Point();
Point(double x, double y);
void print();
};Point::Point()
{
cout << " In Point() default constructor " << endl ;
x = 0.0 ;
y = 0.0 ;
}Point::Point(double xx, double yy)
{
cout << " In Point(double,double) constructor " << endl ;
x = xx ;
y = yy ;
}void Point::print()
{
cout << " (x,y) = (” << x << “,” << y << “)” ;
}
int main ( )
{Point p1;
Point p2(17,45.75);cout << “\n Point P1: " ;
p1.print();cout << “\n Point P2: " ;
p2.print();return EXIT_SUCCESS ;
}
**Output
**
In Point() default constructor
In Point(double,double) constructor
Point P1: (x,y) = (0,0)
Point P2: (x,y) = (17,45.75)







