
Recitations
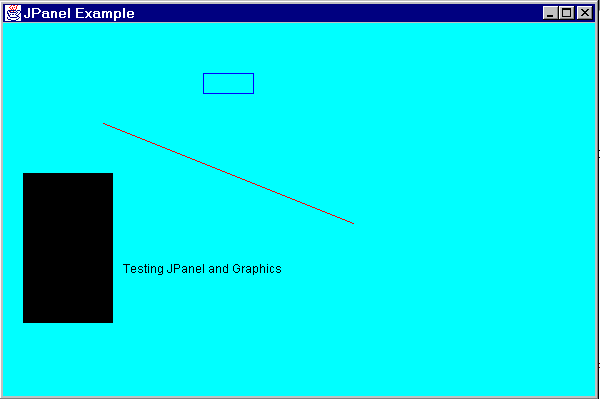
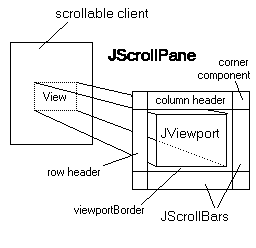
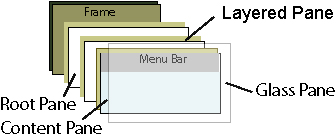
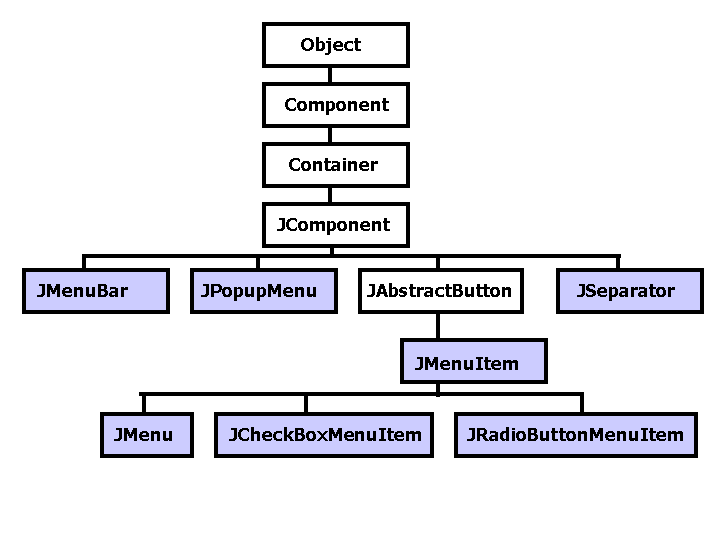



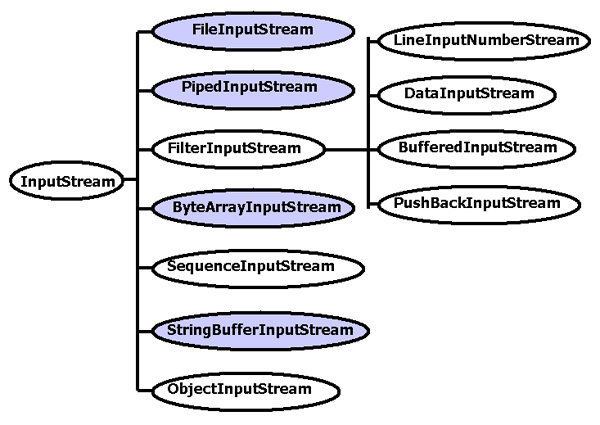
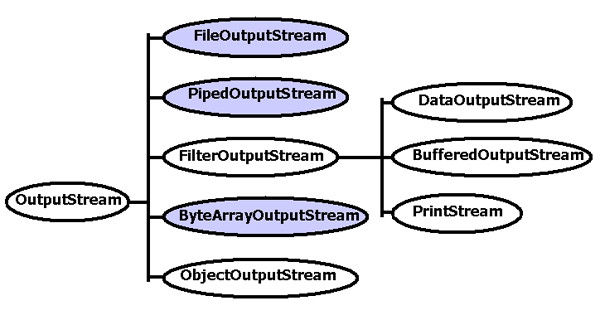
Course Info
Instructor
As Taught In
Fall
2000
Level
Learning Resource Types
grading
Exam Solutions
grading
Exams
assignment
Presentation Assignments
assignment_turned_in
Programming Assignments with Examples
assignment
Written Assignments







