
Mitigating Gender Bias slides (PDF - 1.6MB)
Learning Objectives
- Explore steps and principles involved in building less-biased machine learning modules.
- Explore two classes of technique, data-based and model-based techniques for mitigating bias in machine learning.
- Apply these techniques to the UCI adult dataset.
Content
The repository for this module can be found at Github - ML Bias Fairness.
Defining algorithmic/model bias
Bias or algorithmic bias will be defined as systematic errors in an algorithm/model that can lead to potentially unfair outcomes.
Bias can be quantified by looking at discrepancies in the model error rate for different populations.
UCI adult dataset
The UCI adult dataset is a widely cited dataset used for machine learning modeling. It includes over 48,000 data points extracted from the 1994 census data in the United States. Each data point has 15 features, including age, education, occupation, sex, race, and salary, among others.
The dataset has twice as many men as women. Additionally, the data shows income discrepancies across genders. Approximately 1 in 3 of men are reported to make over $50K, whereas only 1 in 5 women are reported to make the same amount. For high salaries, the number of data points in the male population is significantly higher than the number of data points in the female category.
Preparing data
In order to prepare the data for machine learning, we will explore different steps involved in transforming data from raw representation to appropriate numerical or categorical representation. One example is converting native country to binary, representing individuals whose native country was the US as 0 and individuals whose native country was not the US as 1. Similar representations need to be made for other attributes such as sex and salary. One-hot encoding can be used for attributes where more than two choices are possible.
Binary coding was chosen for simplicity, but this decision must be made on a case-by-case basis. Converting features like work class can be problematic if individuals from different categories have systematically different levels of income. However, not doing this can also be problematic if one category has a population that is too small to generalize from.
Illustrating gender bias
We apply the standard ML approach to the UCI adult dataset. The steps that are followed are 1) splitting the dataset into training and test data, 2) selecting model (MLPClassifier in this case), 3) fitting the model on training data, and 4) using the model to make predictions on test data. For this application, we will define the positive category to mean high income (>$50K/year) and the negative category to mean low income (<=$50K/year).
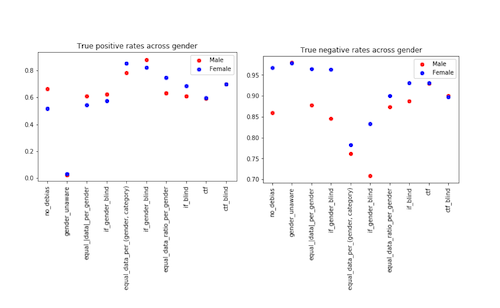
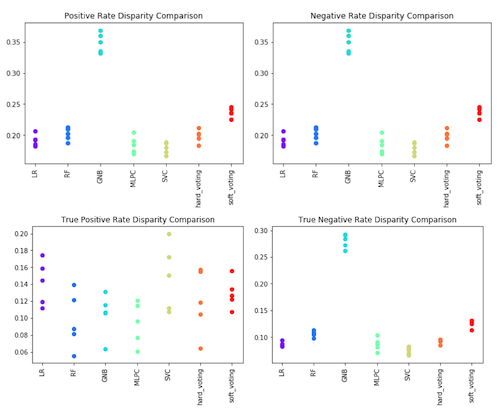
The model results show that the positive rates and true positive rates are higher for the male demographic. Additionally, the negative rate and true negative rates are higher for the female demographic. This shows consistent disparities in the error rates between the two demographics, which we will define as gender bias.
Exploring data-based debiasing techniques
We hypothesize that gender bias could come from unequal representation of male and female demographics. We attempt to re-calibrate and augment the dataset to equalize the gender representation in our training data. We will explore the following techniques and their outcomes. We will compare the results after describing each approach.
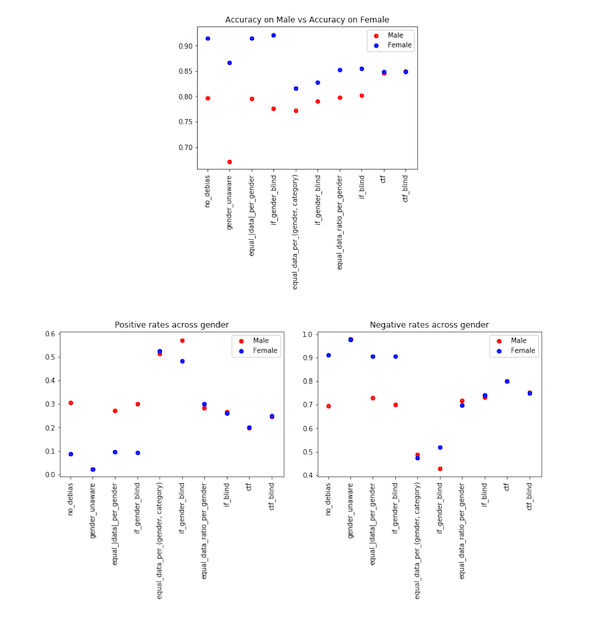
Debiasing by unawareness: we drop the gender attribute from the model so that the algorithm is unaware of an individual’s gender. Although the discrepancy in overall accuracy does not change, the positive, negative, true positive, and true negative rates are much closer for the male and female demographics.
Equalizing the number of data points: we attempt different approaches to equalizing the representation. The different equalization criteria are #male = #female, #high income male = #high income female, #high income male/#low income male = #high income female/#low income female. One of the disadvantages of equalizing the number of data points is that the dataset size is limited by the size of the smallest demographic. Equalizing the ratio can overcome this limitation.
Augment data with counterfactuals: for each data point Xi
We see varying accuracy across different approaches on accuracy for the male and female demographics, as shown in the plot below. The counterfactual approach is shown to be the best at reducing gender bias. We see similar behavior for the positive rates and negative rates as well as the true positive and true negative rates.
Model-based debiasing techniques
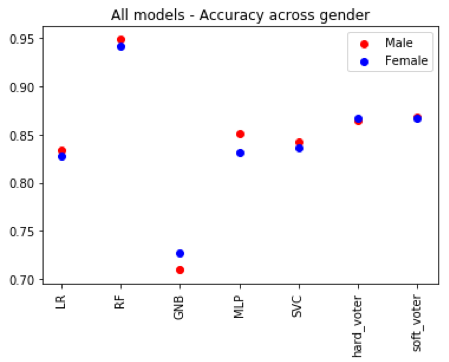
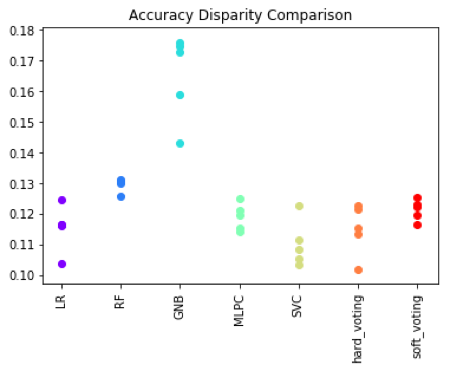
Different ML models show different levels of bias. By changing the model type and architecture, we can observe which ones will be less biased for this application. We examine single and multi-model architectures. The models that will be considered are support vector, random forest, KNN, logistic regression, and MLP classifiers. Multi-model architectures involve training a group of different models that make a final prediction based on consensus. Two approaches can be used for consensus; hard voting, where the final prediction is the majority prediction among the models and soft voting, where the final prediction is the average prediction. The following plots show the differences in overall accuracy and the discrepancies between accuracy across gender.
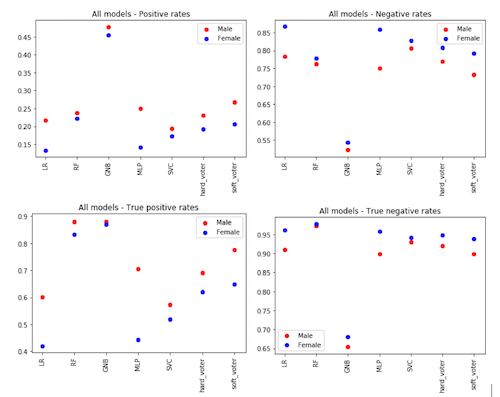
It is also important to compare the results of the models across multiple training sessions. For each model type, five instances of the model were trained and compared. Results are shown the plot below. We can see that different models have different variability in performance for different metrics of interest.
References
Dua, D. and Graff, C. (2019). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science.
Bishop, Christopher M. Pattern Recognition and Machine Learning. New York: Springer 2006. ISBN: 9780387310732.
Hardt, Moritz. (2016, October 7). “Equality of opportunity in machine learning.” Google AI Blog.
Zhong, Ziyuan. (2018, October 21). “A tutorial on fairness in machine learning.” Toward Data Science.
Kun, Jeremy. (2015, October 19). “One definition of algorithmic fairness: statistical parity.”
Olteanu, Alex. (2018, January 3). “Tutorial: Learning curves for machine learning in Python.” DataQuest.
Garg, Sahaj, et al. 2018. “Counterfactual fairness in text classification through robustness.” arXiv preprint arXiv:1809.10610.
Wikipedia contributors. (2019, September 6). “Algorithmic bias.” In Wikipedia, The Free Encyclopedia.
Contributions
Content presented by Audace Nakeshimana (MIT).
This content was created by Audace Nakeshimana and Maryam Najafian (MIT).







