
Case Study on Pulmonary Health slides (PDF - 1.2MB)
Learning Objectives
- Present a case study on pulmonary health diagnostics.
- Explore the influence of representative data on accuracy.
Content
Introduction
Pulmonary diseases, including asthma, COPD, allergic rhinitis, and others can have significant detrimental health impacts if undetected. In remote areas with limited access to healthcare, they can often go undiagnosed and untreated. The motivation for this work was to develop a screening tool for community healthcare workers to determine if patients who were presenting symptoms of pulmonary disease actually have pulmonary disease.
To develop the tool, data was collected from 303 patients who sought medical care at health clinics between 2015 and 2018 in Pune, India. Patient data was collected at health clinics from two exams, a mobile diagnostic kit developed by Dr. Fletcher’s group and a set of measurements from a Pulmonary Function Test lab by the research team, and health diagnoses were performed by medical staff with a focus on asthma, allergic rhinitis, and COPD.
Study design
This exploration of representative sampling on accuracy was conducted across two protected variables: gender and income. For income considerations, patients were categorized as either low-income or high-income. The overall approach to the bias study was to divide the dataset into a larger training data superset and a test dataset. A logistic regression model with L2 regularization was used to make predictions on disease.
To train the model, training data subsets were randomly sampled from the superset that intentionally introduced imbalances along protected variables. For example, with regards to income, training data subsets ranged from 50% high-income to 50% low-income and 87.5% high-income to 12.5% low-income. To account for stochastic error, this process was run 1000 times for each test. The area under the curve of the receiver operating characteristic curve was used as the metric for accuracy.
Results
The results for predictive accuracy for AR, Asthma, and COPD are shown below. The data shows no significant decrease in algorithm accuracy as gender imbalances are introduced in the data. It is important to note that protected variables do not necessarily affect outcome variables and that lack of representativeness may not always introduce bias or unfairness into models.
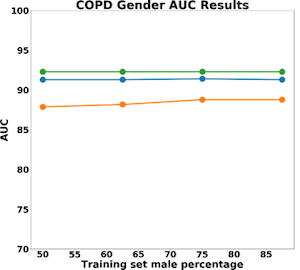
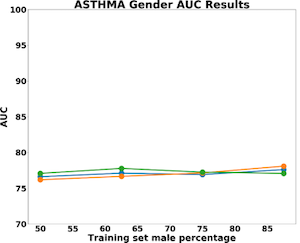
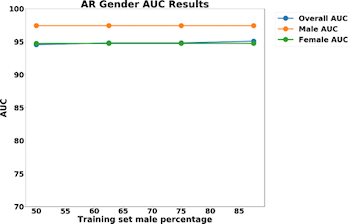
In our dataset, we found that smoking heavily correlated with gender. 55% of men reported that they were non-smokers, whereas 100% of women reported that they were non-smokers. As a result, the population of women was more homogenous, allowing for higher predictive accuracy.
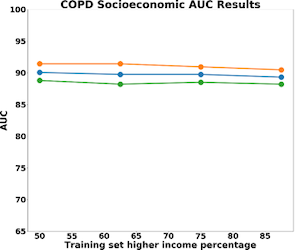
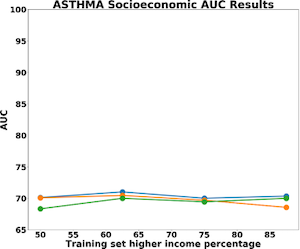
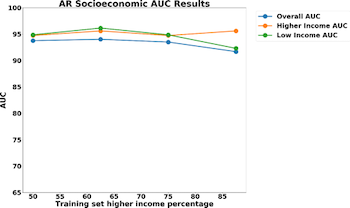
The results for predictive accuracy for AR, Asthma, and COPD are shown below. Again, we see little difference in accuracy as we change representativeness within the sample. COPD is the most sensitive to socio-economic status with a 4% difference in model accuracy for high-income and low-income populations. Asthma and allergic rhinitis show no difference in performance.
Contributions
Content presented by Amit Gandhi (MIT).
The research and content for this module was conducted by Rich Fletcher and Olasubomi Olubeko (MIT) in collaboration with the Chest Research Foundation. Additional funding for the project was provided by NSF and the Vodafone Americas Foundation.







