
Unit Overview

|
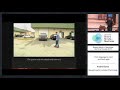
How do we recognize physical events in a dynamic visual scene? Andrei Barbu and his colleagues have developed a system that can generate a sentence like “The person to the right of the bin picked up the backpack” from a video clip portraying this action. (Image © Journal of Artificial Intelligence Research. All rights reserved. This content is excluded from our Creative Commons license. Source: Yu, H., N. Siddharth, A. Barbu, and J. M. Siskind. “A Compositional Framework for Grounding Language Inference, Generation, and Acquisition in Video.” J. Artif. Intell. Res. (JAIR) 52 (2015): 601-713.) |
The ability to obtain and communicate complex knowledge about a visual scene, in order to answer simple questions about the objects, agents, and actions portrayed, requires the integration of vision with language understanding. In this unit, you will learn about the state-of-the-art in automated question answering systems; models that leverage visual recognition and tracking with language understanding to describe the content of a video in linguistic terms; and a system that can understand stories. Turning to biology, you will learn about the representations of semantic information in the brain as revealed by fMRI studies.
Boris Katz describes key elements of the START system, an online question answering system that has been operating for over two decades, and compares its capabilities to IBM’s Watson system that can beat human players at Jeopardy.
Andrei Barbu shows how the simple ability to compare an English sentence and a video clip can form the basis for many tasks such as recognition, image and video retrieval, generation of video captions, question answering, and language acquisition.
Patrick Winston addresses a cognitive ability that distinguishes human intelligence from that of other primates: The ability to tell, understand, and recombine stories. The Genesis story understanding system is a powerful and flexible platform for exploring this capability.
Guest speaker Tom Mitchell shows how the neural representations of language meaning can be understood using machine learning methods that can decode fMRI signals to reveal the semantics of words experienced by a viewer.
Unit Activities
Useful Background
- Introductions to machine learning, neuroscience
Videos and Slides

Further Study
Additional information about the speakers’ research and publications can be found at their websites:
Berzak, Y., A. Barbu, et al. “Do You See What I Mean? Visual Resolution of Linguistic Ambiguities.” (PDF - 2.4MB) Proceedings of the 2015 Conference on Empirical Methods on Natural Language Processing (2015): 1477–87.
Huth, A. G., S. Nishimoto, et al. “A Continuous Semantic Space Describes the Representation of Thousands of Object and Action Categories Across the Human Brain.” Neuron 76, no. 6 (2012): 1210–24.
Katz, B. “START Natural Language Question Answering System. " (online resource)
Mitchell, T., S. V. Shinkareva, et al. “Predicting Human Brain Activity Associated with the Meanings of Nouns.” (PDF) Science 320 (2008): 1191–95.
Siddharth, N., A. Barbu, et al. “Seeing What You’re Told: Sentence-Guided Activity Recognition in Video.” (PDF) IEEE Conference on Computer Vision and Pattern Recognition (2014).
Sudre, G., D. Pomerleau, et al. “Tracking Neural Coding of Perceptual and Semantic Features of Concrete Nouns.” (PDF - 1.3MB) NeuroImage 62 (2012): 451–63.
Wehbe, L., B. Murphy, et al. “Simultaneously Uncovering the Patterns of Brain Regions Involved in Different Story Reading Subprocesses.” (PDF - 1.1MB) PLOS One (2014): 1–19.
Winston, P. H. “The Genesis Story Understanding and Story Telling System: A 21st Century Step toward Artificial Intelligence.” (PDF) Center for Barins, Minds & Machines, Memo no. 019 (2014).
———. “The Right Way.” Advances in Cognitive Systems 1 (2012): 23–36.
Yu, H., N. Siddharth, et al. “A Compositional Framework for Grounded Language Inference, Generation, and Acquisition in Video." Journal of Artificial Intelligence Research 52 (2015): 601–713.







