
Unit Overview
|
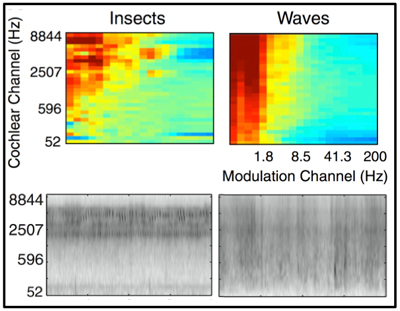
How do we recognize the source of a sound texture, such as the sound of insects or waves? Josh McDermott and colleagues propose a model of this process that uses statistics of the frequency content of the sounds, and the modulation of this content over time, depicted in these spectrograms (bottom) and plots of modulation power (top). (Courtesy of Elsevier, Inc., http://www.sciencedirect.com. Used with permission. Source: McDermott, Josh H., and Eero P. Simoncelli. “Sound texture perception via statistics of the auditory periphery: evidence from sound synthesis.” Neuron 71, no. 5 (2011): 926-940.) |
How do we use the auditory signals generated by the ear to recognize events in the world, such as running water, a crackling fire, music, or conversation between speakers? In this unit, you will learn about the structure and function of the auditory system, the nature of sound, and how it can be used to recognize sound textures and speech. Physiologically inspired models of these processes capture the neural mechanisms by which the brain processes this information.
Part 1 of Josh McDermott’s lecture provides an overview of the auditory system and neural encoding of sound, and explores the problem of recognizing sound textures. A model of this process exploits statistical properties of the frequency content of an incoming sound.
Part 2 of Josh McDermott’s lecture delves more deeply into the ability of human listeners to recognize sound textures, using the synthesis of artificial sounds as a powerful tool to test a model of this process. The lecture also examines other cues used to analyze the content of a scene from the sounds that it produces.
Nancy Kanwisher presents fMRI studies that led to the discovery of regions of auditory cortex that are specialized for the analysis of particular classes of sound such as music and speech.
Hynek Hermansky addresses the problem of speech processing, beginning with the structure of speech signals, how they are generated by a speaker, how speech is initially processed in the brain, and key aspects of auditory perception. The lecture then reviews the history of speech recognition in machines.
Part 2 of Hynek Hermansky’s lecture examines the key challenge of recognizing speech in a way that is invariant to large speaker variations and unwanted noise in the auditory signal, and how insights from human audition can inform models of speech processing.
A panel of experts in vision and hearing reflect on the similarities and differences between these two modalities, and how exploitation of the synergies between the two may accelerate the pace of research on the study of vision and audition in brains and machines.
Unit Activities
Useful Background
- Introductions to neuroscience and statistics
- The lecture by Hynek Hermansky lecture requires background in signal processing
Videos and Slides






Further Study
Additional information about the speakers’ research and publications can be found at their websites:
Hermansky, H., J. R. Cohen, et al. “Perceptual Properties of Current Speech Recognition Technology.” (PDF - 1.7MB) Proceedings of the IEEE 101, no. 9 (2013): 1968–85.
McDermott, J. H. “The Cocktail Party Problem.” (PDF) Current Biology 19, no. 22 (2009): R1024–27.
———. “Audition.” (PDF - 1.1MB) In Oxford Handbook of Cognitive Neuroscience Two Volume Set (Oxford Library of Psychology), Edited by K. N. Ochsner and S. Kosslyn. Oxford University Press, 2013. ISBN: 9780195381597.
McDermott, J. H., M. Schemitsch, et al. “Summary Statistics in Auditory Perception.” (PDF - 2.9MB) Nature Neuroscience 16, no. 4 (2013): 493–98.
McDermott, J. H., and E. P. Simoncelli. “Sound Texture Perception via Statistics of the Auditory Periphery: Evidence from Sound Synthesis.” Neuron 71 (2011): 926–40.
Norman-Haignere, S., N. Kanwisher, et al. “Distinct Cortical Pathways for Music and Speech Revealed by Hypothesis-Free Voxel Decomposition.” (PDF - 10.3MB) Neuron 88, no. 6 (2015): 1281–96.
Yamins, D., and J. J. DiCarlo. “Using Goal-Driven Deep Learning Models to Understand Sensory Cortex.” Nature Neuroscience 19, no. 3 (2016): 356–65.







